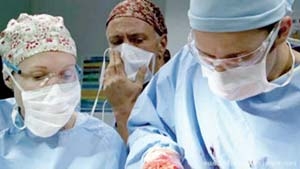
به گزارش لایوساینس اخیرا دانشمندان یک میانجی مغز- ماشین ساختهاند که به ارتباط برقرار کردن مجدد افرادی که دیگر نمیتوانند صحبت کنند با خواندن امواج مغزی آنها با استفاده از الکترودهایی که در مغز آنها کار گذاشته شده است، کمک میکند.
متاسفانه نشان داده شده است که این میانجیها بسیار کند هستند، یعنی حدود یک کلمه را در دقیقه تایپ میکنند، که مکالمات و تعاملات اجتماعی معمول را تقریبا ناممکن میکند.
اکنون دانشمند علوم اعصاب شناختی، فرانک گونتر در دانشگاه بوستون و همکارانش یک میانجی مغز- ماشین را ارائه کردهاند که از الکترودهایی استفاده میکند که برای پژوهش در مورد گفتار همزمان به طور مستقیم درون مغز کاشته شده است.
گوتنر در این باره گفت: "حرف زدن افراد مبتلا به فلجهای شدید که در حال حاضر نمیتوانند صحبت کنند، از طریق یک کامپیوتر لپتاپ باید به زودی امکانپذیر شود."
این دانشمندان با یک مرد داوطلب 26 ساله کار کردند که به خاطر یک سکته مغزی در 16 سالگیاش دچار فلج تقریبا کامل شده بود. آنها یک الکترود را که دو سیم داشت به درون بخشی از مغز که به طراحی و اجرای حرکات مربوط به گفتار کمک میکنند، کاشتند.
این الکترود پیامهای مغزی را هنگامی که داوطلب تلاش میکرد سخن بگوید ثبت میکردند و آنها را به طور بیسیم از میان پوست سر منتقل میکردند تا وارد یک سینتیسایزر گفتار وارد شود. تاخیر میان فعالیت مغز و برونده صدا به طور میانگین تنها 50 میلیثانیه بود که تقریبا به همان مقداری است که هنگام صحبت معمولی دیده میشود.
گوتنر یادآور شد: "او کاملا هیجانزده بود، به خصوص در چند روز اول که ما از این سیستم استفاده کردیم، زمانی که داشت به خصوصیات آن عادت میکرد. من مطمئنم که پیشرفت کار از دیدگاه او و از دیدگاه ما در آن زمان کند به نظر میرسید. با این وجود از اینکه میتوانست از حرفهایی که میخواست بزند، به طور همزمان پسخوراند (فیدبک) صوتی دریافت میکرد، بسیار هیجانزده بود، و خوشحال بود که در تمام این تجربیات به همراه ما سخت کار کرده است."
این پژوهشگران بر حروف صدادار متمرکز شده بودند، چرا که این اجزای صدادار برای دههها مورد بررسی قرار گرفته بودند و نرمافزارهایی در دسترس بود که به سرعت آنها را ترکیب کند. دقت تولید حروف صدادار بوسیله داوطلبان با سینتیسایزر به انجام تمرین به سرعت از 45 درصد به 89 درصد در طول یک دوره 25 جلسه در پنج ماه افزایش یافت.
گوتنر توضیح داد: "داوطلب ما توانست توالی صدادار به صداداری مانند "آه- ای"که یک حرکت گفتاری نسبتا ساده است، تولید کند. چالش بعدی تولید حروف بیصدا بود. این کا رنیاز به نوع متفاوتی از سینتیسایزر دارد- یک سینتیسایزر تکلمی، که در آن کاربر حرکات یک "زبان مجازی" را کنترل خواهد کرد."
او افزود: "چنین سینتیسایزری امکان تولید همه کلمات را خواهد داد، اما کاربر مجبور خواهد بود که سیستم پیچیدهتری را برای کنترل به کار برد. این سینتیسایزر، به همراه افزایش شمار الکترودهایی که میتوانند پیامهای را از روی پوست سر ضبط و منتقل کنند، باید نهایتا به سیستمی بینجامد که به کاربر اجازه دهد کلمات و جملات کامل را تولید کند."
سیستم فعلی از دادههای تنها دو سیم استفاده میکند. گوتنر گفت: "در طول یک سال امکان کاشتن سیستمی با 16 سیم وجود دارد. این کار به ما اجازه خواهد داد تا بسیاری سلولهای عصبی بسیار بیشتری اتصال پیدا کنیم، و در نتیجه کنترل بهتری بر سینتیسایزر داشته باشیم و گفتار بسیار بهتری تولید کنیم."
مشروح این یافتهها در شماره 9 دسامبر ژورنال PLoS ONE آمده است.